Issue 42: Are GPTs Websites?
Or are they perhaps something else altogether?


Dear reader,
Food For Thought

The GPT Store cometh! The week this issue (42) is published, OpenAI will offer its own official version of an "App Store" for GPTs. This store will feature community use cases of GPTs, create a new kind of market with new rules for money, deluge us with many poorly thought out GPTs, and legitimize truly novel experiences yet to be uncovered. All at the same time!
In part II of the holiday issue, I made this prediction:
GPT agents begin to pop up in places QR menus and PoS iPads exist, people get used to talking to agents in a variety of scenarios (high confidence)
I'd like to use this issue to substantiate that prediction.
Let's open with a question with a non obvious answer. What is a website?

In the most brutal definition, websites are readonly pages of information. Due to the technical realities of the ARPANet era, moving large packets of data (think HD video or MMO games) reliably from computers physically located in different geographical locations was not a trivial problem. As such, static text-only webpages were the first websites. Much like a printed piece of paper, webpages were distributed on demand by visiting a unique address, known as a URL.
But right out the gate, websites were special. Inside web pages themselves, creators were able to link to other pages. This meant that information could spread as nodes in a graph, that could create interesting non linear paths. A piece of paper physically located in Boise could point to another piece of paper in Baton Rouge, which in turn points to a piece of paper in Singapore.
This linking feature was very important, because there was (and is, to this day) no way to randomly stumble upon websites continuously (this is why search engines perpetually index the web for new data). In other words, jumping from computer address to computer address is a discrete jump, where in the physical world, travel is contiguous. This is important, because this means that the Internet itself is sparse, and has a tendency to amalgamate.
As a medium, the internet is defined by a built-in performance incentive. In real life, you can walk around living life and be visible to other people. But you can’t just walk around and be visible on the internet—for anyone to see you, you have to act.
-- Trick Mirror: Reflections on Self-Delusion (affiliate link)
Because of this fact, information on websites became silos by default. Each "acre of land" was only farmed upon by its creators. Nearly 30 years after the CERN website launch, this is still the case. It takes place on much larger silos – those of YouTube, Reddit, and Twitch streams, but the concept is still the same: information at an address that can be linked elsewhere. In this 30 year period, the world itself has become Internet native, spawning brand new economies, and creating write access to pages that have created emergent properties like influencers. The silos of a TikToker or a LinkedIn influencer is write access to a largely readonly Intranet. Your @ is not your friendships, it is a link on two sub-pages within a social network domain (@alice follows (points to) @bob, @bob follows (points to) @cheryl and @alice).
What about GPTs?
GPTs are also information. Specifically, GPTs and agents are a thin layer of information on a deep layer of contextual knowledge. I.e GPTs are subject matter experts for foundational knowledge stacks. The graph of data is still there, it is merely implicit, rather than the explicit discrete jumps of the world wide web. The subject matter is within the foundational knowledge graph. Your role as a GPT creator is to introduce a few new concepts inside a context window, things the model doesn't know, and the model will create implicit links to the rest of itself.
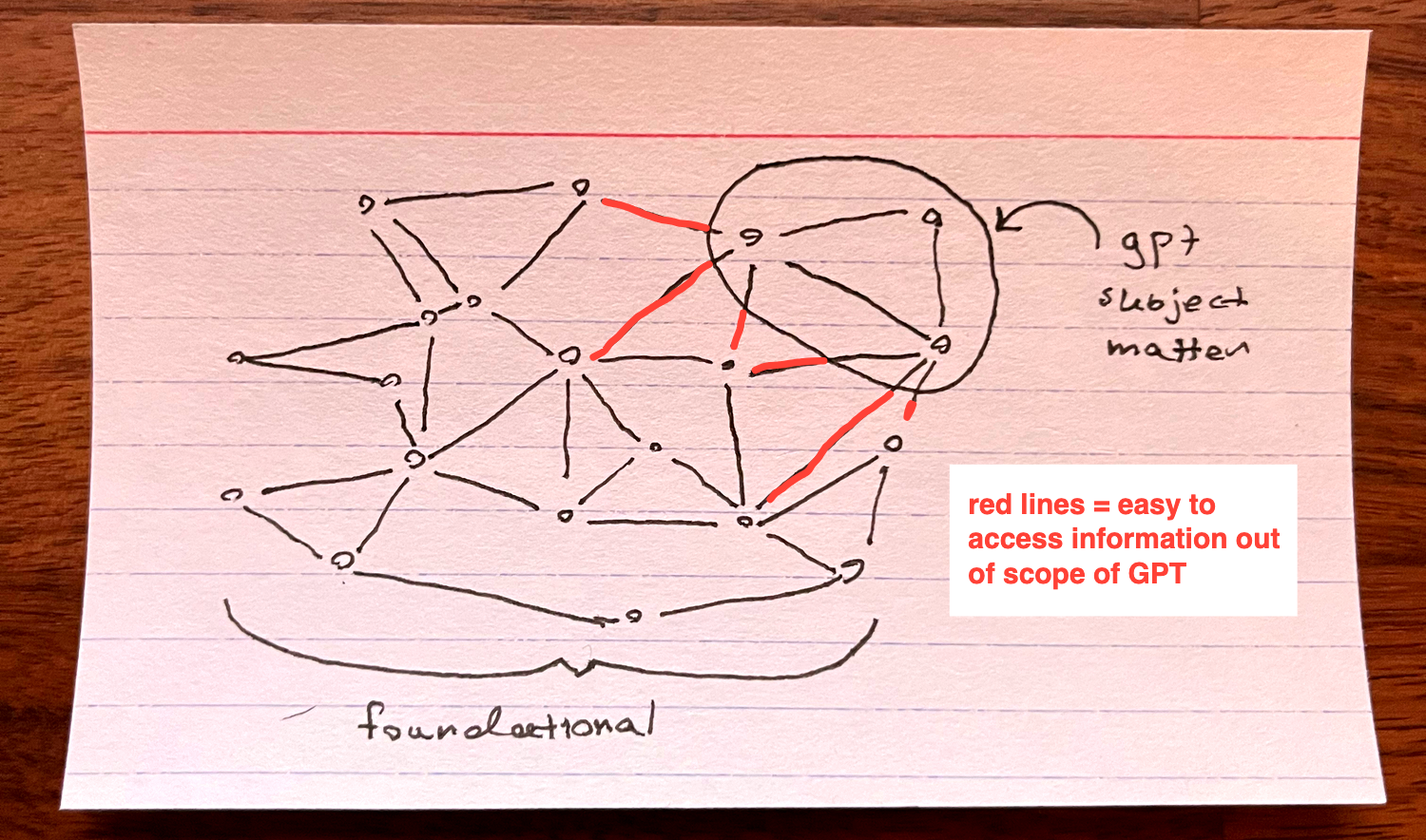
GPTs do differ from websites in one immediate facet. GPTs are fundamentally conversational. Instead of readonly, the user is compelled to engage with the bot, to interact and in fact, assistants will do nothing unless prompted.
There are at minimum two types of GPTs that will begin to crop up:
- Smart Forms - Forms today cannot be inquired against, they only demand in silence. Why do you need my middle name, Mr. Form? What is an EIN? How long until I hear back on average? A GPT will be able to stop mid form to teach you these things and then continue to complete the form. Excitingly, these can be branching programmatic forms as well – if user says x, the GPT responds with y, etc.
- Local Information Load Balancer - Just like websites gained network value in the 2000's, so too will GPTs create local networks for local problems. Questions about local restaurant menus, conversational audio guides for museums fall under this category. These are the QR code thin assistant layer, the "do you have this brand of tissue?" "Yes, aisle 5" (here are two examples of load balancers I've made: an interactive conversation with a blog post I wrote, and a World of Warcraft Season of Discovery rune helper). With API actions these plugins will surely have a major impact on how people exchange and expect to receive up to date information.
In sum, I make the claim that a GPT is a subject matter expertise layer on top of a massive implicit graph of conversational data. In a sense, a website is this as well, each URL holding subject matter expertise on running marathons, or ducks, or whatever. With the architecture of the web, the sites were siloed from one another, taking manual work from a human to leap from concept to concept. As the Internet has evolved we are now in a world where explicit graphs live in information silos: YouTube recommendation feeds, mutual follows. GPTs take the implicit graphs and give it context, they place subject matter expertise of what you know into context of what you didn't say.
We're in the primordial era of something really, really cool.
Ye Olde Newsstand - Weekly Updates
 Bram Adams
Bram Adams
I've come to the realization that these "core dumps/instabrams" are really just the "fun newsletter" a.k.a. shitposting. Micro time capsules, snapshots of links that will largely disappear into the void of time
On My Nightstand - What I'm Reading
Today the Internet is often described as an information superhighway; its nineteenth-century precursor, the electric telegraph, was dubbed the ‘‘highway of thought.’’
TCP/IP on January 1, 1983—an event that many would call the actual birth of the Internet.
-- The Dream Machine (affiliate link)
the internet generally minimizes the need for physical action: you don’t have to do much of anything but sit behind a screen to live an acceptable, possibly valorized, twenty-first-century life.
-- Trick Mirror: Reflections on Self-Delusion (affiliate link)
Whatever you’re into, there’s a website for that. We all play “a fractional part in some quite trivial matter,” as Kierkegaard says. And this is soothing.
-- The World Beyond Your Head: On Becoming an Individual in an Age of Distraction (affiliate link)
Thanks for reading, and see you next Sunday!
ars longa, vita brevis,
Bram
P.S. If you like what you read on this newsletter, forward it to a friend! It really helps!



